TLDR
[claude] come up with 3-4 bullet points on what was accomplished in this chapter.
Motivation
[claude] come up with a distrilled paragraph argument for why we should care about muli-variate regression. Here’s a section of Richard McElreath’s text statistical Rethinking
- Statistical “control” for confounds. A confound is something that misleads us about a causal influence—there will be a more precise definition in the next chapter. The spurious waffles and divorce correlation is one possible type of confound, where the confound (southernness) makes a variable with no real importance (Waffle House density) appear to be important. But confounds are diverse. They can hide real important variables just as easily as they can produce false ones.
- Multiple causation. A phenomenon may arise from multiple causes. Measurement of each cause is useful, so when we can use the same data to estimate more than one type of influence, we should. Furthermore, when causation is multiple, one cause can hide another.
- Interactions. The importance of one variable may depend upon another. For ex- ample, plants benefit from both light and water. But in the absence of either, the other is no benefit at all. Such interactions occur very often. Effective inference about one variable will often depend upon consideration of others.
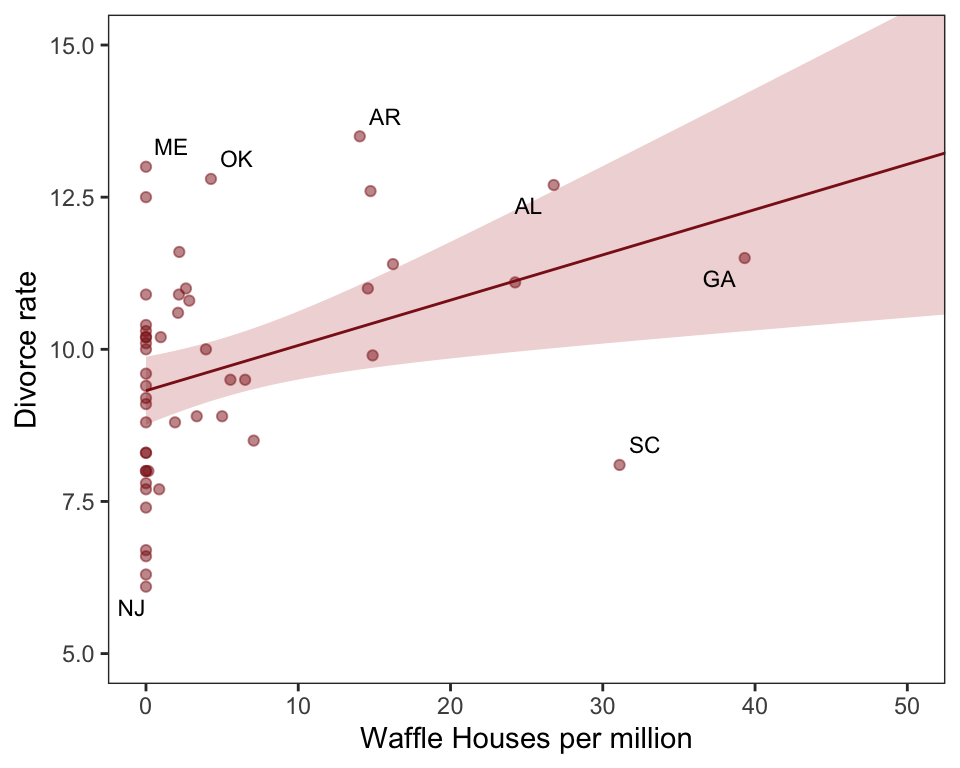
Claude give a quick description of the waffle divorce data set : Data for the individual States of the United States, describing number of Waffle House diners and various marriage and demographic facts.
Format Location : State name Loc : State abbreviation Population : 2010 population in millions MedianAgeMarriage: 2005-2010 median age at marriage Marriage : 2009 marriage rate per 1000 adults Marriage.SE : Standard error of rate Divorce : 2009 divorce rate per 1000 adults Divorce.SE : Standard error of rate WaffleHouses : Number of diners South : 1 indicates Southern State Slaves1860 : Number of slaves in 1860 census Population1860 : Population from 1860 census PropSlaves1860 : Proportion of total population that were slaves in 1860
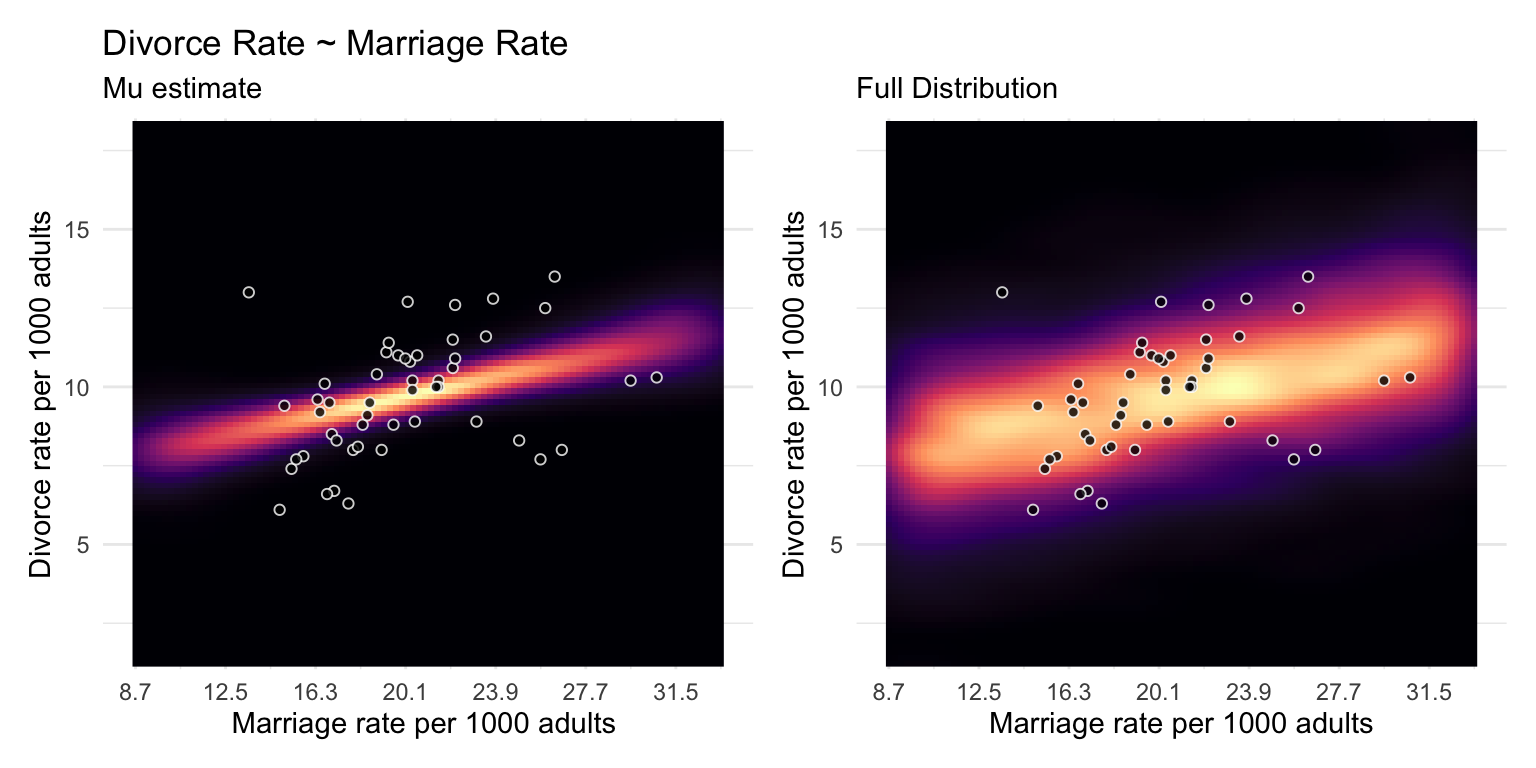
Most likely a spurious correlation, waffles don’t cause divorces nor vice versa
Spurious Correlation
Excerpt from Richard McElreath: “Let’s leave waffles behind, at least for the moment. An example that is easier to understand is the correlation between divorce rate and marriage rate (Figure 5.2). The rate at which adults marry is a great predictor of divorce rate, as seen in the left-hand plot in the figure. But does marriage cause divorce? In a trivial sense it obviously does: One cannot get a divorce without first getting married. But there’s no reason high marriage rate must be correlated with divorce.”
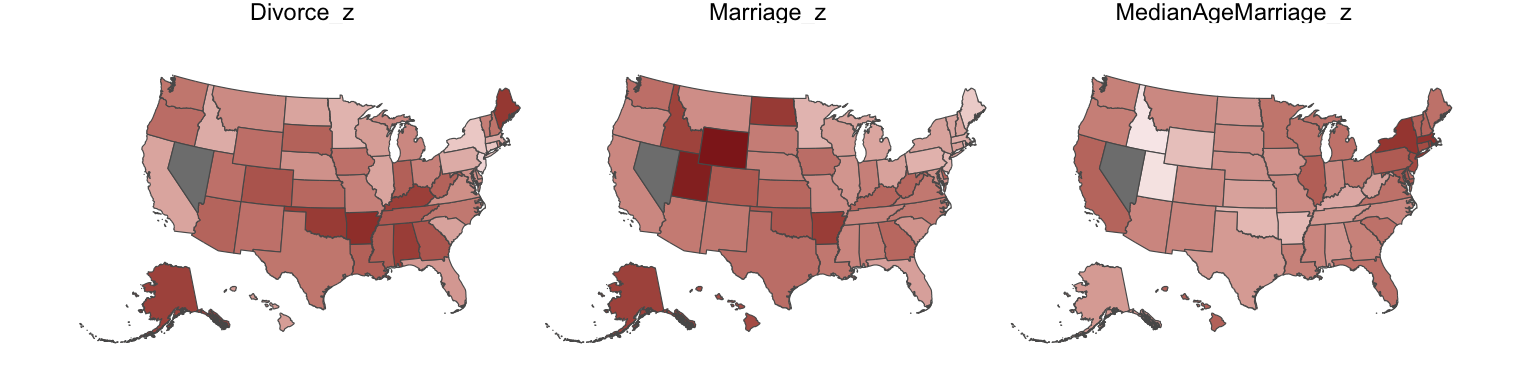
We see that Divorce rate is high in the south and low in the north midwest and mid atlantic. Marriage rate is high in
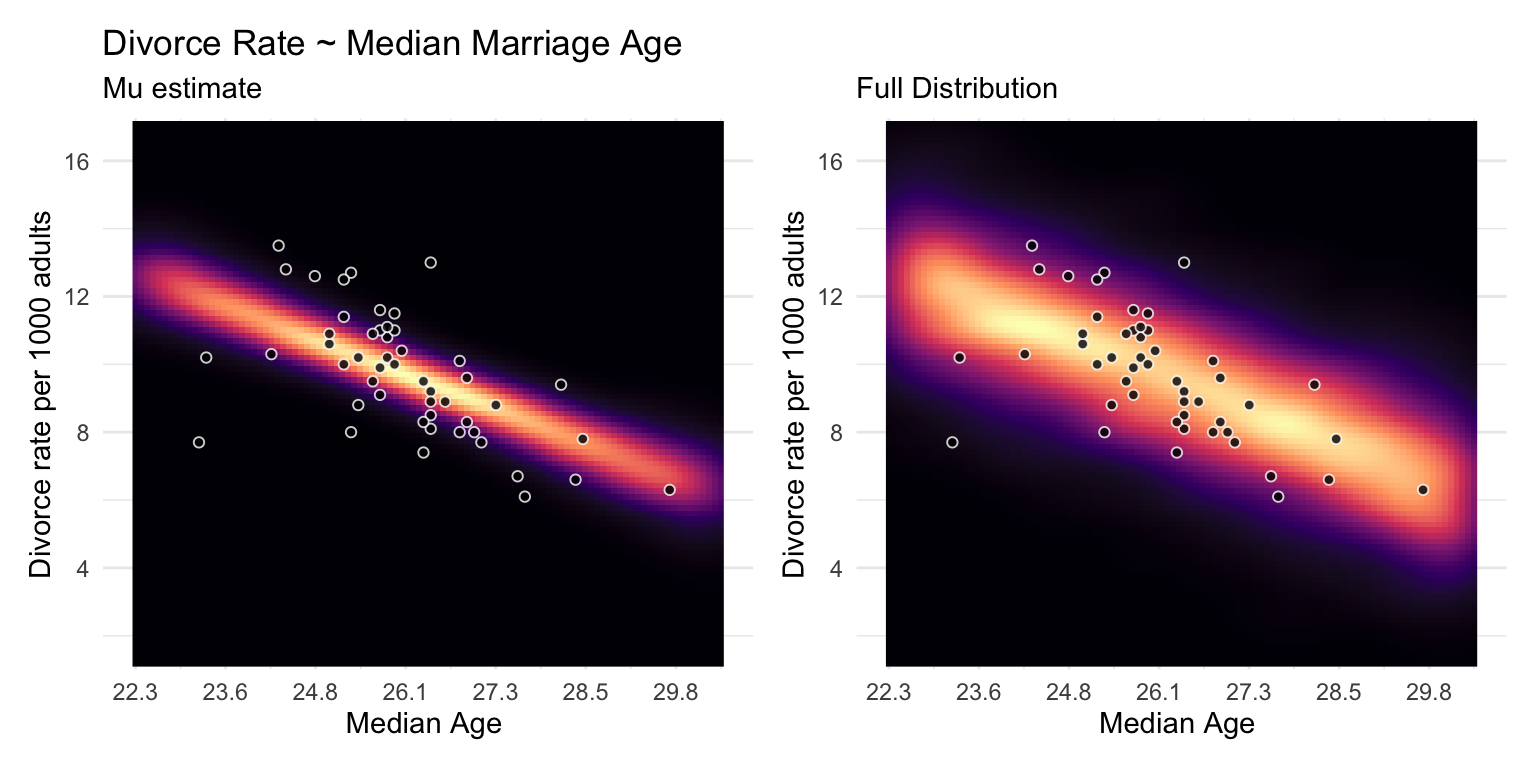
Median Marriage Age Model
\[ \textbf{b5.1} \]
\[ \text{Divorce}_i \sim \text{Intercept} + \beta_1 \text{Median Age Marriage}_i \]
b5.1 <-
brm(data = WaffleDivorce,
family = gaussian,
Divorce ~ 1 + MedianAgeMarriage_s,
prior = c(prior(normal(10, 10), class = Intercept),
prior(normal(0, 1), class = b),
prior(uniform(0, 10), class = sigma, ub = 10)),
iter = 2000, warmup = 500, chains = 4, cores = 4,
seed = 5, backend = "cmdstanr", silent = 2,
file = "fits/b05.01")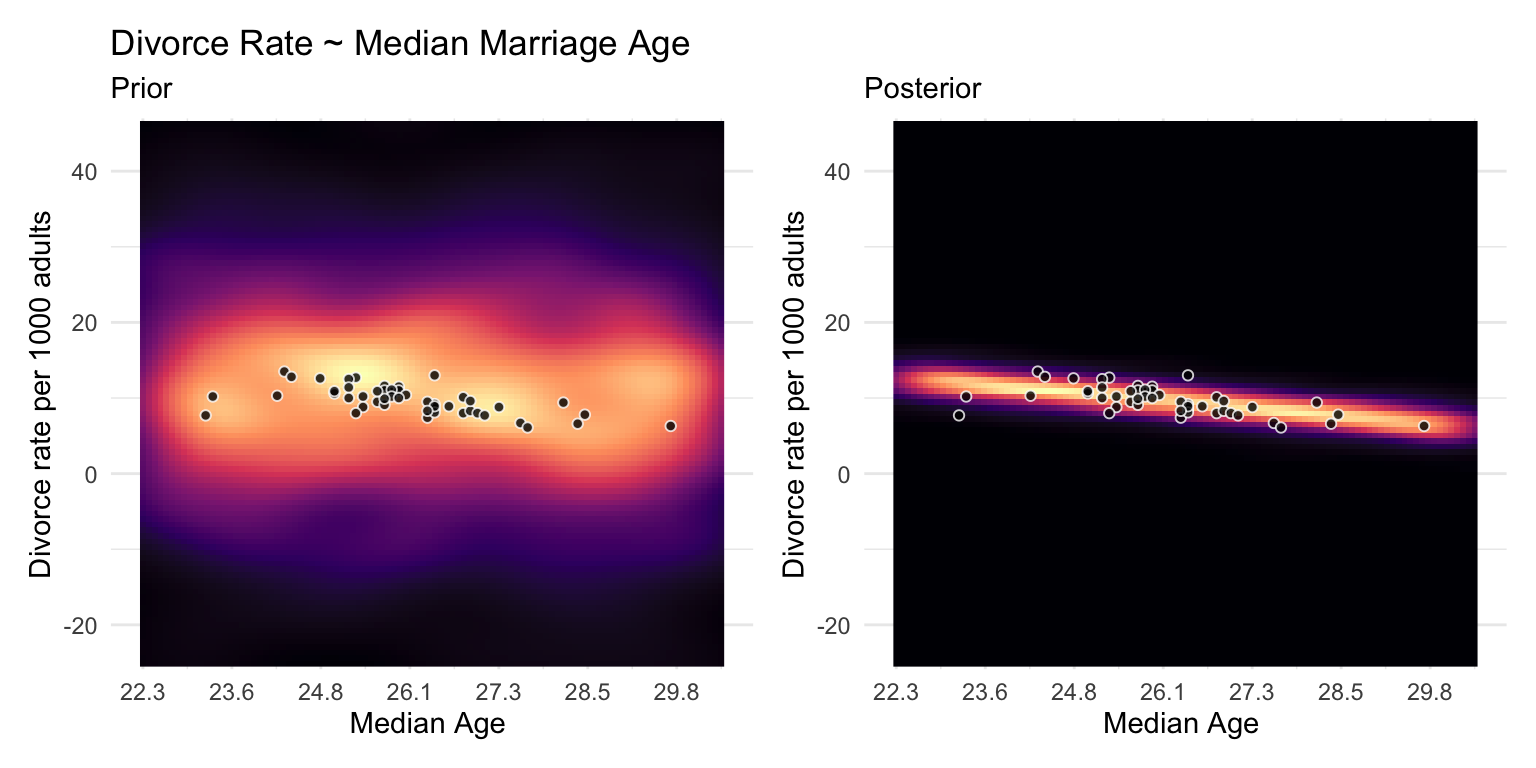
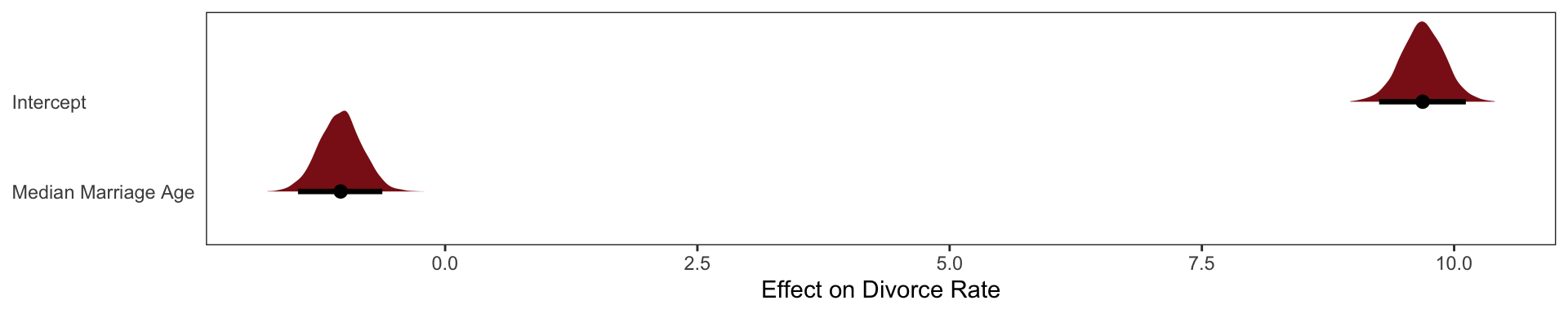
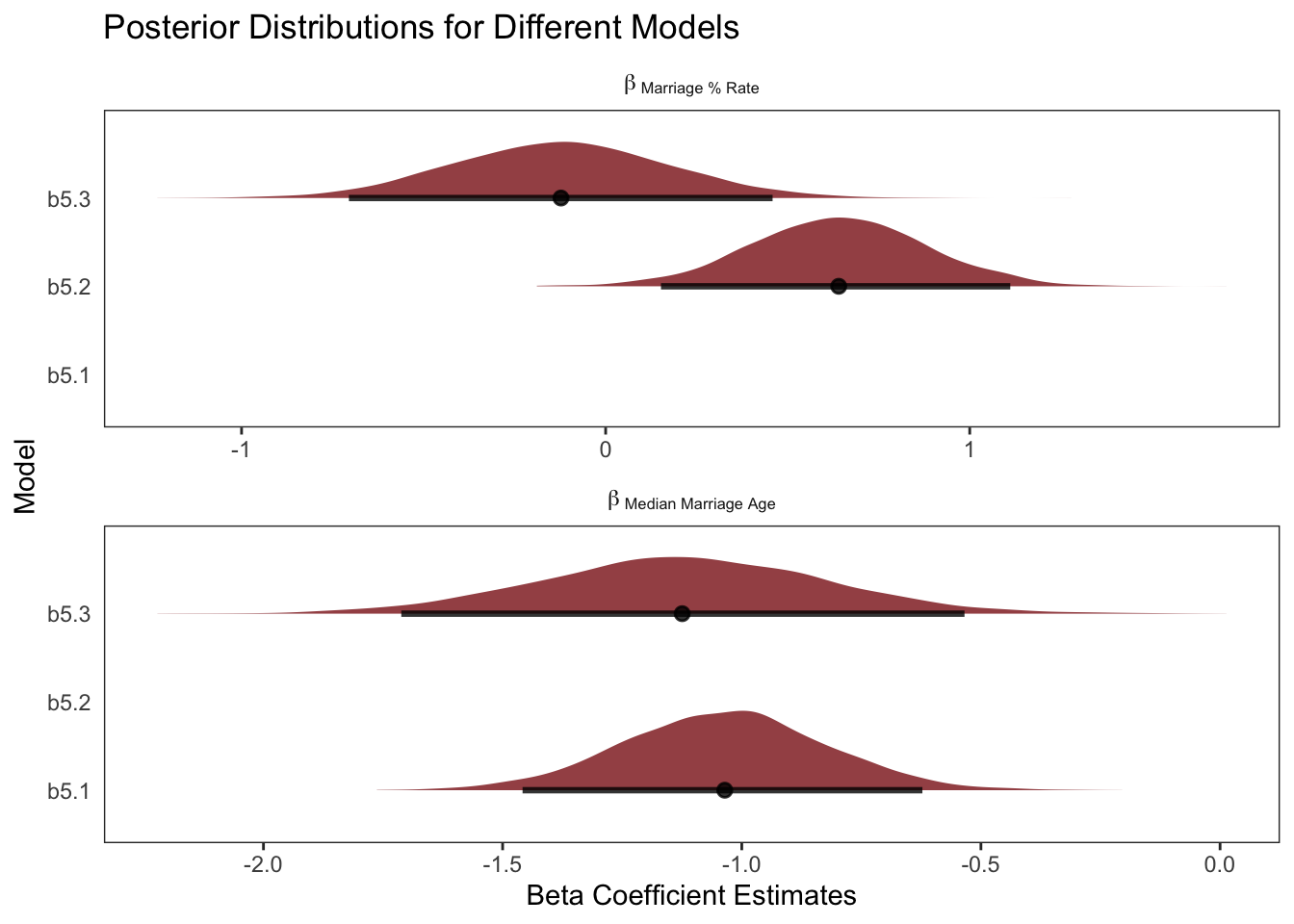
The regression of Divorce Rate on Age of Marriage, tells us only that the total influence of age at marriage is strongly negative with divorce rate.
Marriage Rate
\[ \textbf{b5.2} \]
\[ \text{Divorce}_i \sim \text{Intercept} + \beta_1 \text{Marriage % Rate}_i \]
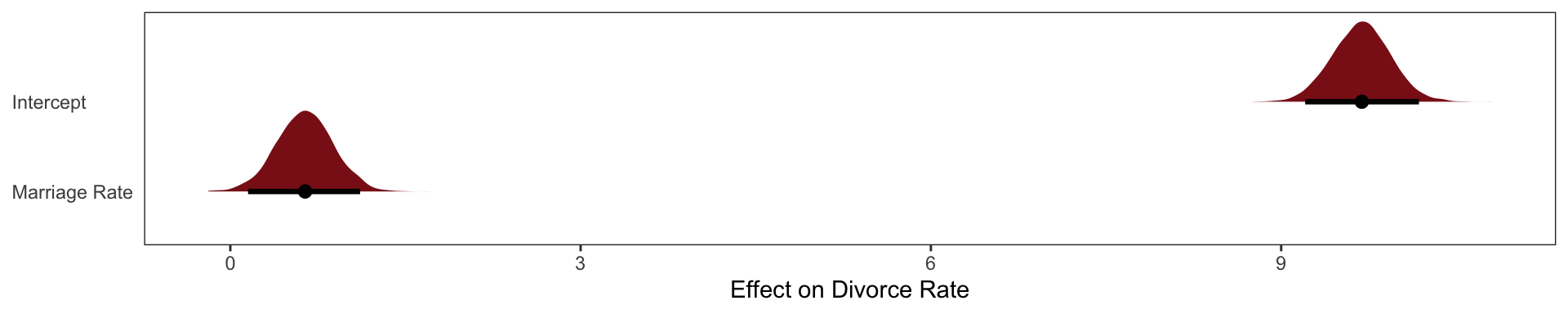
b5.2 <-
brm(data = WaffleDivorce,
family = gaussian,
Divorce ~ 1 + Marriage_s,
prior = c(prior(normal(10, 10), class = Intercept),
prior(normal(0, 1), class = b),
prior(uniform(0, 10), class = sigma, ub = 10)),
iter = 2000, warmup = 500, chains = 4, cores = 4,
seed = 5, backend = "cmdstanr", silent = 2,
file = "fits/b05.02")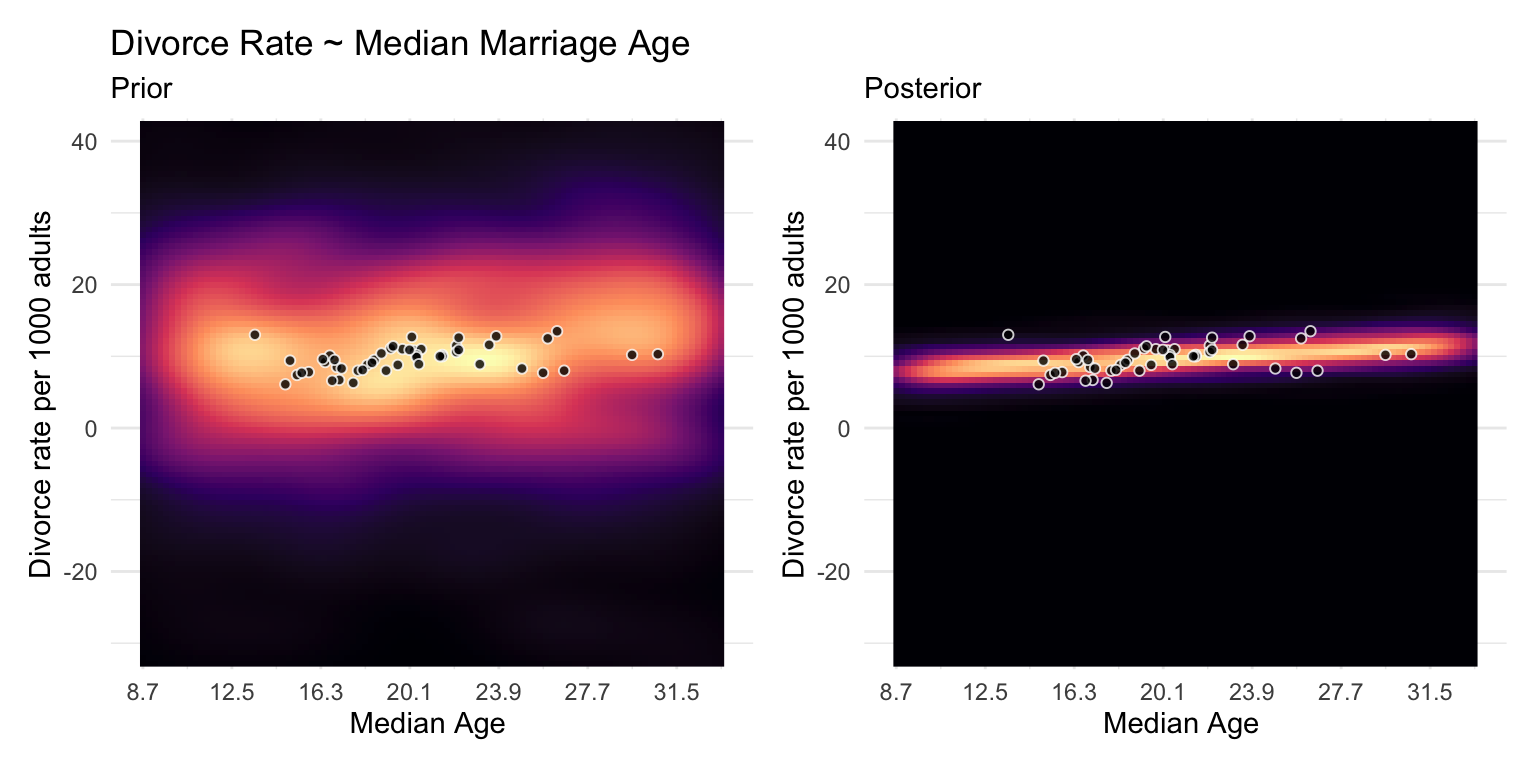
Combined Multi-linear model
\[ \textbf{b5.3} \]
\[ \text{Divorce}_i \sim \text{Intercept} + \beta_1 \text{Marriage % Rate}_i + \beta_2 \text{Median Marriage Age}_i \]
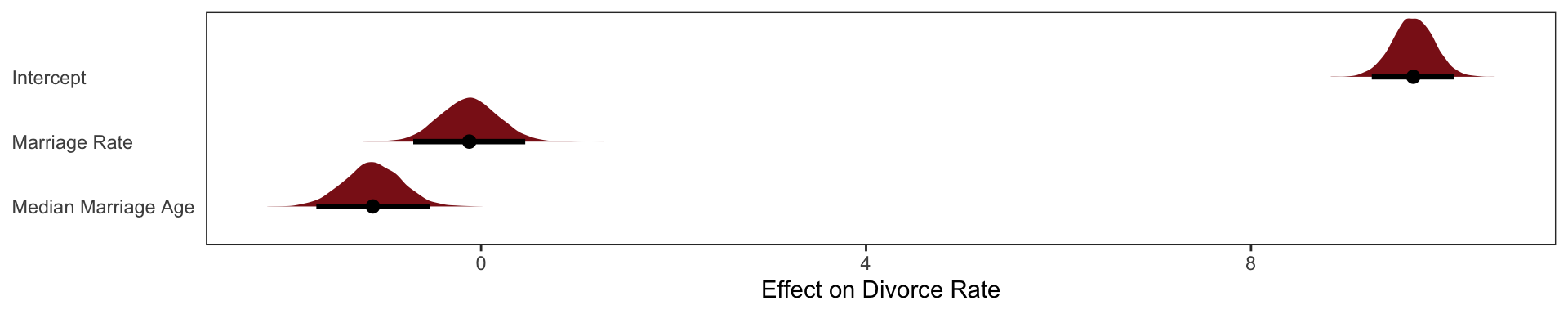
b5.3 <- brm(data = WaffleDivorce,
family = gaussian,
Divorce ~ 1 + Marriage_s + MedianAgeMarriage_s,
prior = c(prior(normal(10, 10), class = Intercept),
prior(normal(0, 1), class = b),
prior(uniform(0, 10), class = sigma, ub = 10)),
iter = 2000, warmup = 500, chains = 4, cores = 4,
seed = 5, backend = "cmdstanr", silent = 2,
file = "fits/b05.031")Diagnosing Multi-linear models
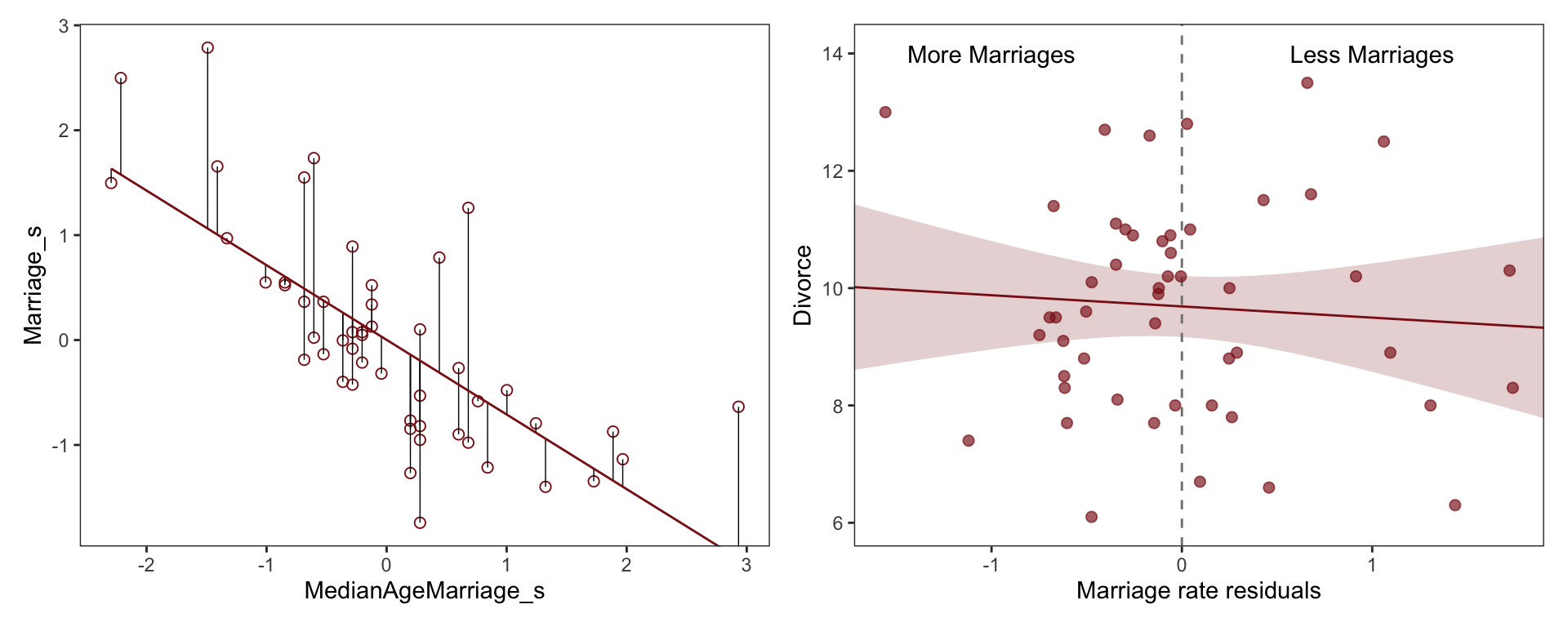
Little relationship between divorce and marriage rates, once we have accounted for the effect of Median Marriage Age
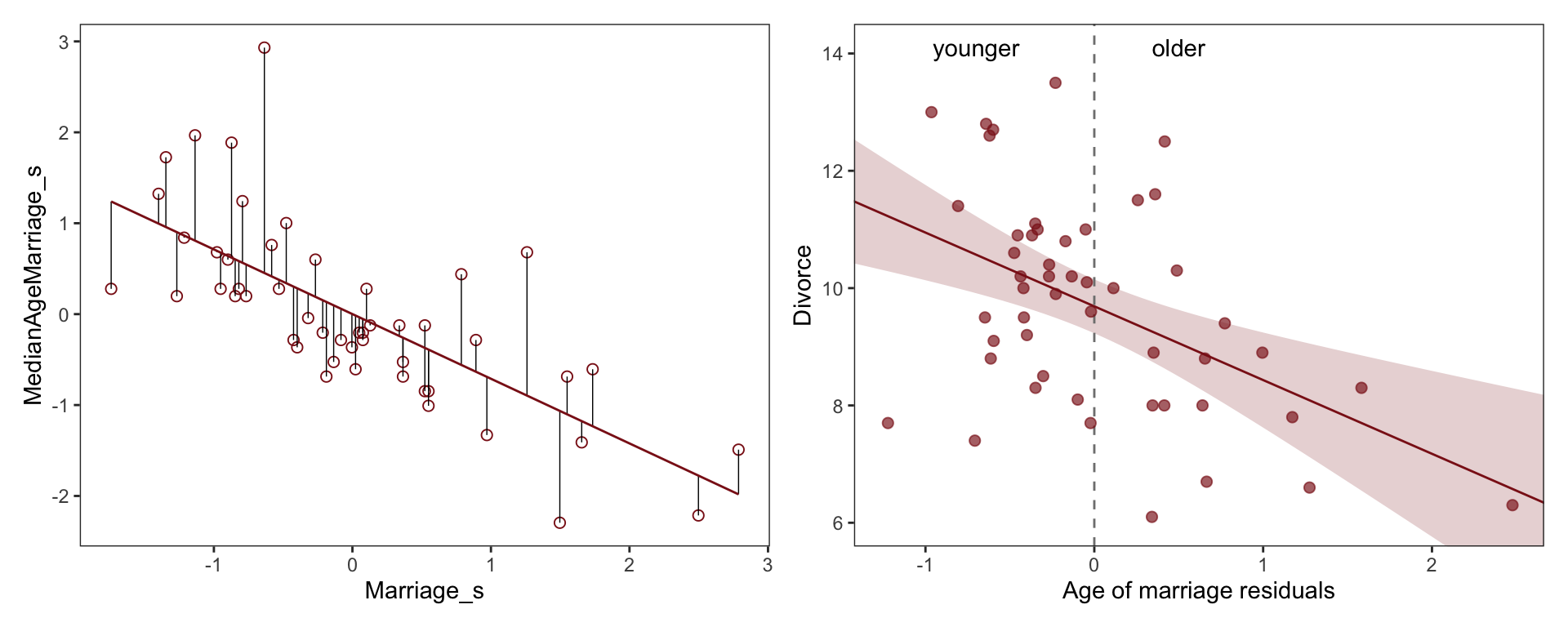
Negative relationship between divorce and marriage age, even after we have accounted for the effect of the Marriage % Rate
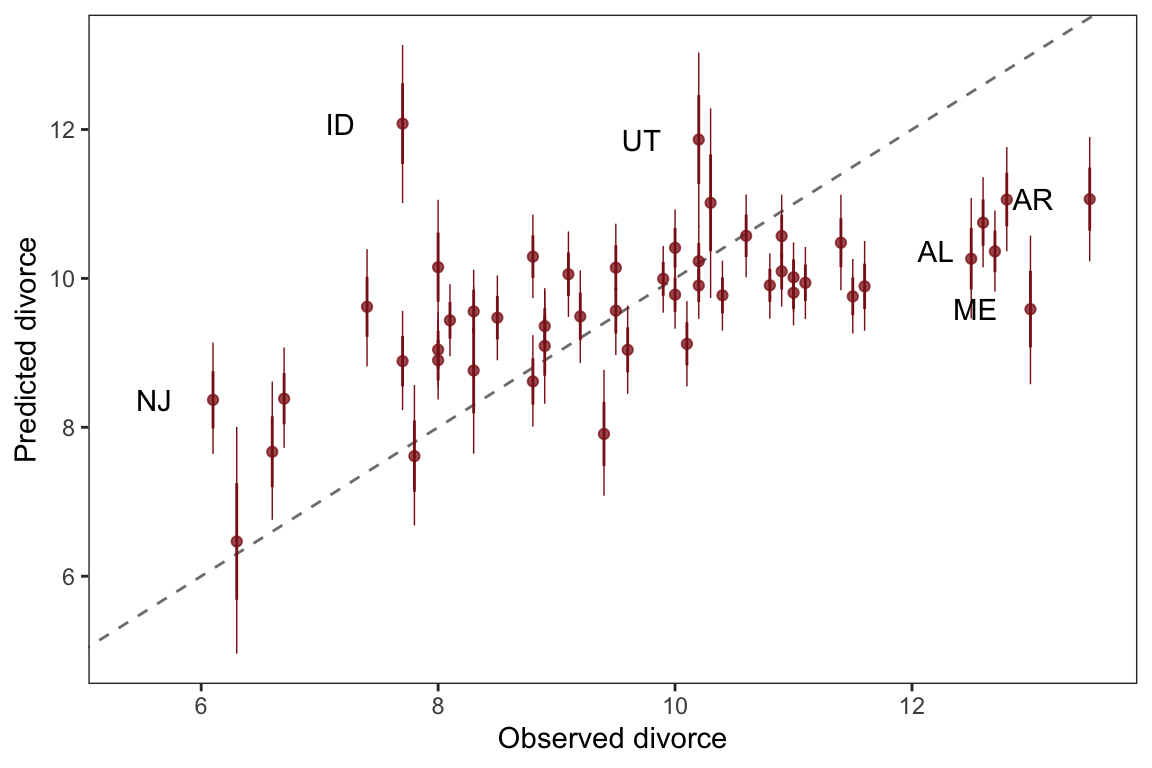
“This procedure also brings home the message that regression models measure the remaining association of each predictor with the out- come, after already knowing the other predictors. In computing the predictor residual plots, you had to perform those calculations yourself. In the unified multivariate model, it all hap- pens automatically. Nevertheless, it is useful to keep this fact in mind, because regressions can behave in surprising ways as a result.”
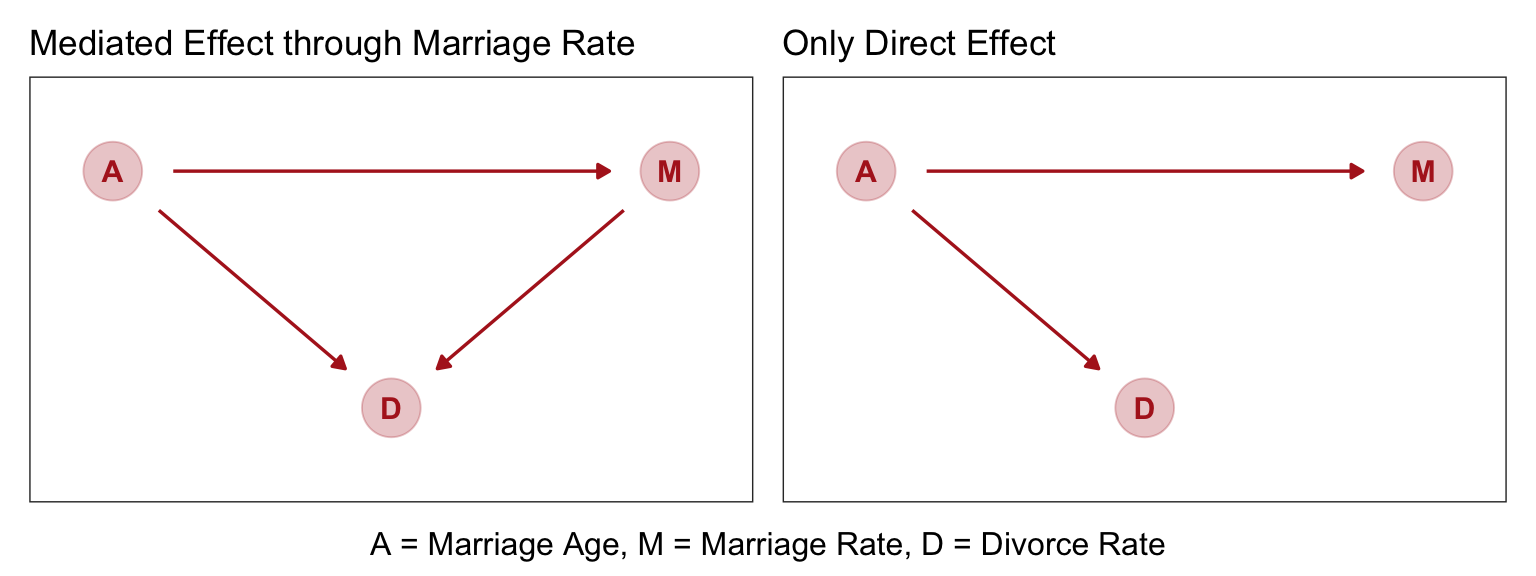
Solving the DAG
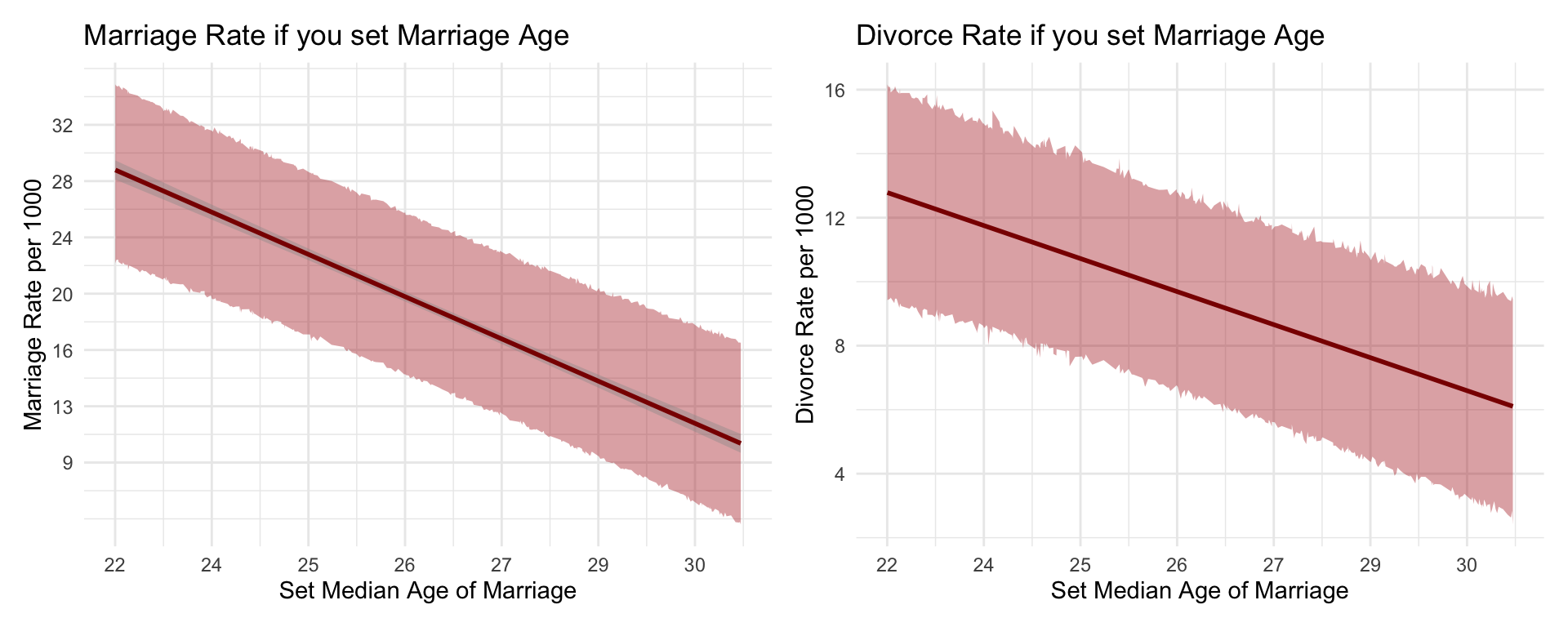
From McElreath, “Age of marriage influences divorce in two ways. First it can have a direct effect, perhaps because younger people change faster than older people and are therefore more likely to grow incompatible with a partner. Second, it can have an indirect effect by influencing the marriage rate. If people get married earlier, then the marriage rate may rise, because there are more young people. Consider for example if an evil dictator forced everyone to marry at age 65. Since a smaller fraction of the population lives to 65 than to 25, forcing delayed marriage will also reduce the marriage rate. If marriage rate itself has any direct effect on divorce, maybe by making marriage more or less normative, then some of that direct effect could be the indirect effect of age at marriage.”
Once we know median age at marriage for a State, there is little or no additional predictive power in also knowing the rate of marriage in that State.
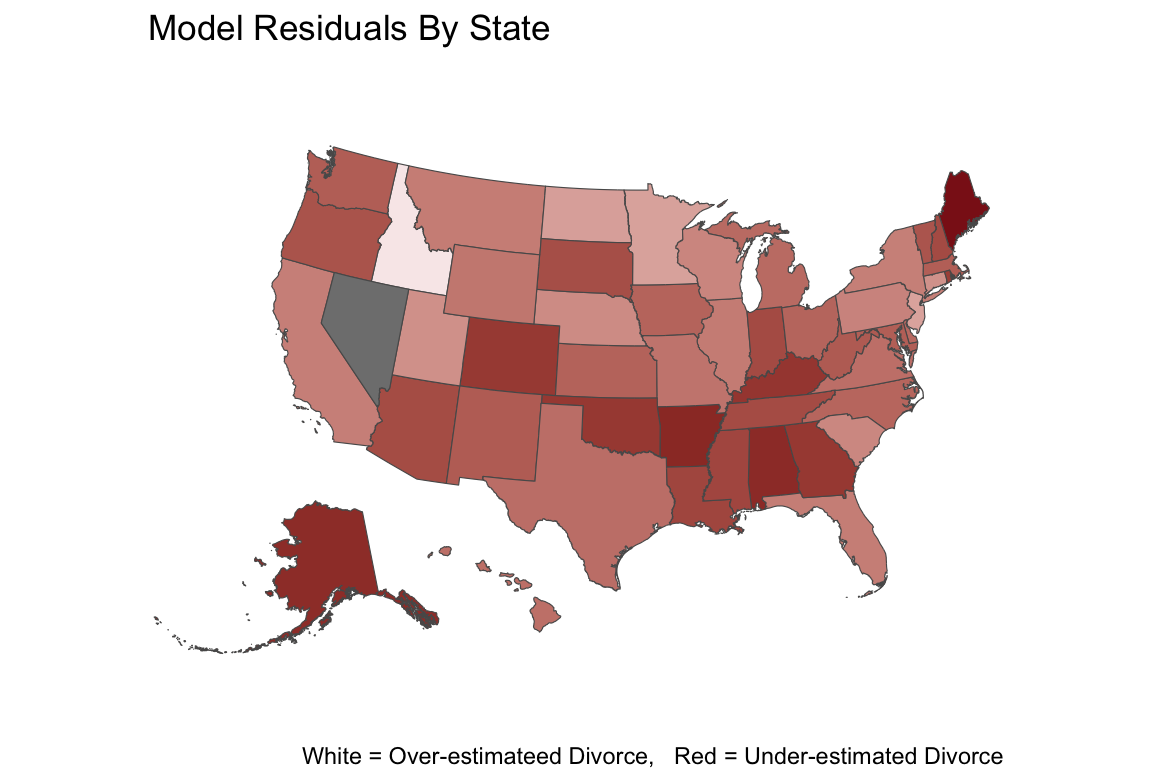
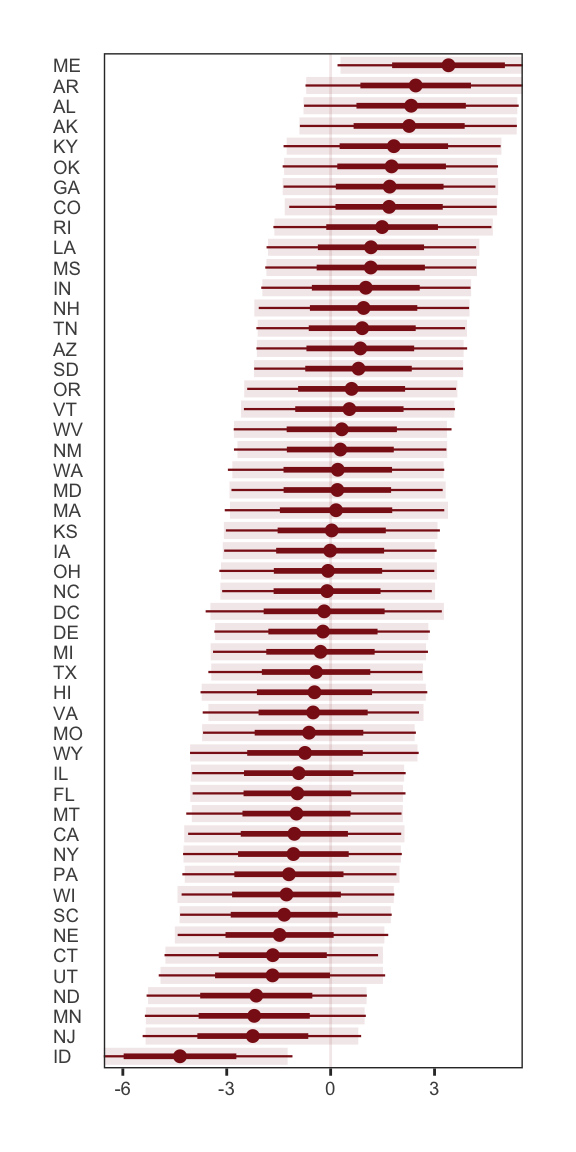
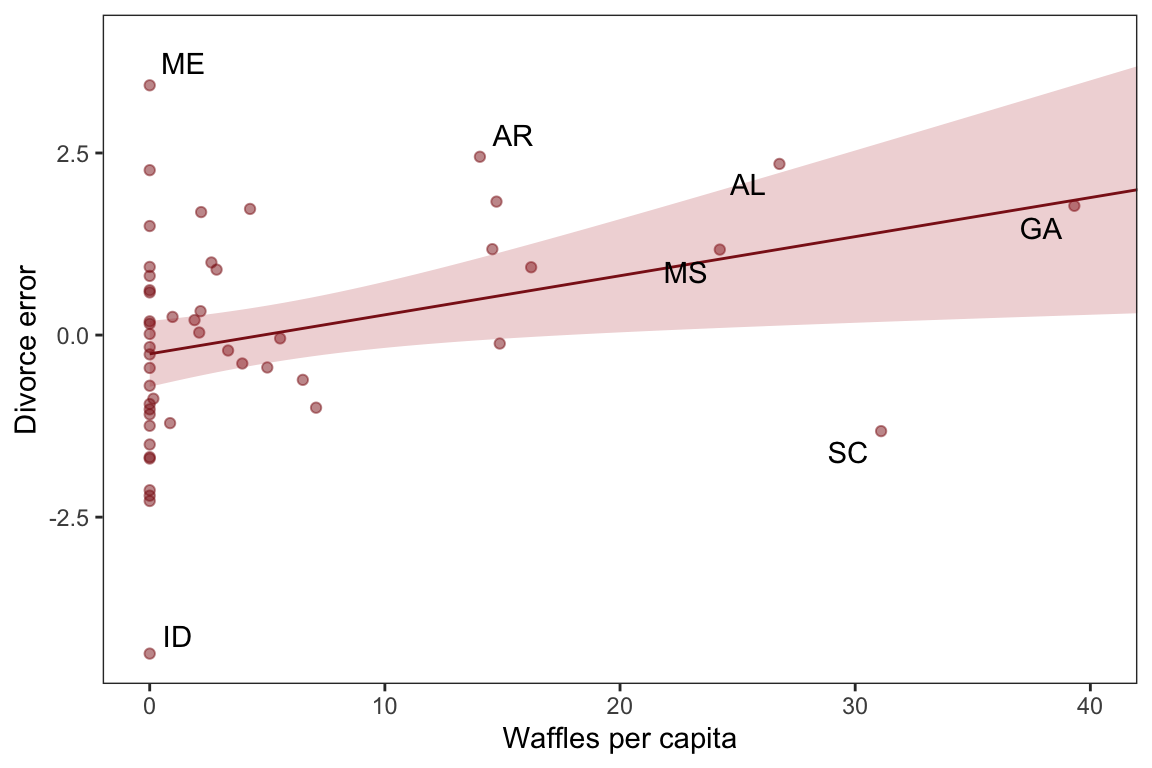
Masked Relationships
New data set Comparative primate milk composition data, from Table 2 of Hinde and Milligan. 2011. Evolutionary Anthropology 20:9-23.
species: Species name
kcal.per.g: Kilocalories per gram of milk
mass: Body mass of mother, in kilograms
neocortex.perc: Percent of brain mass that is neocortex
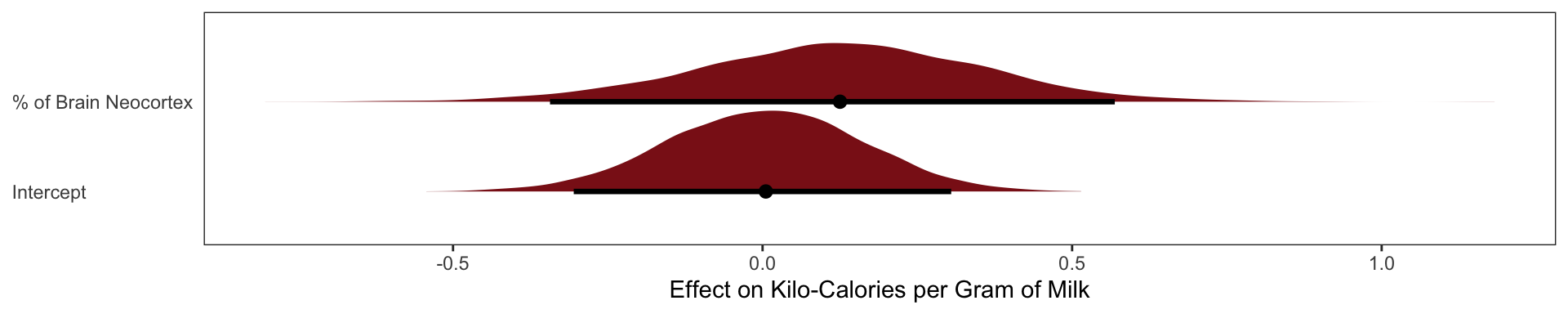
Neocortex % Effect on Milk Calories
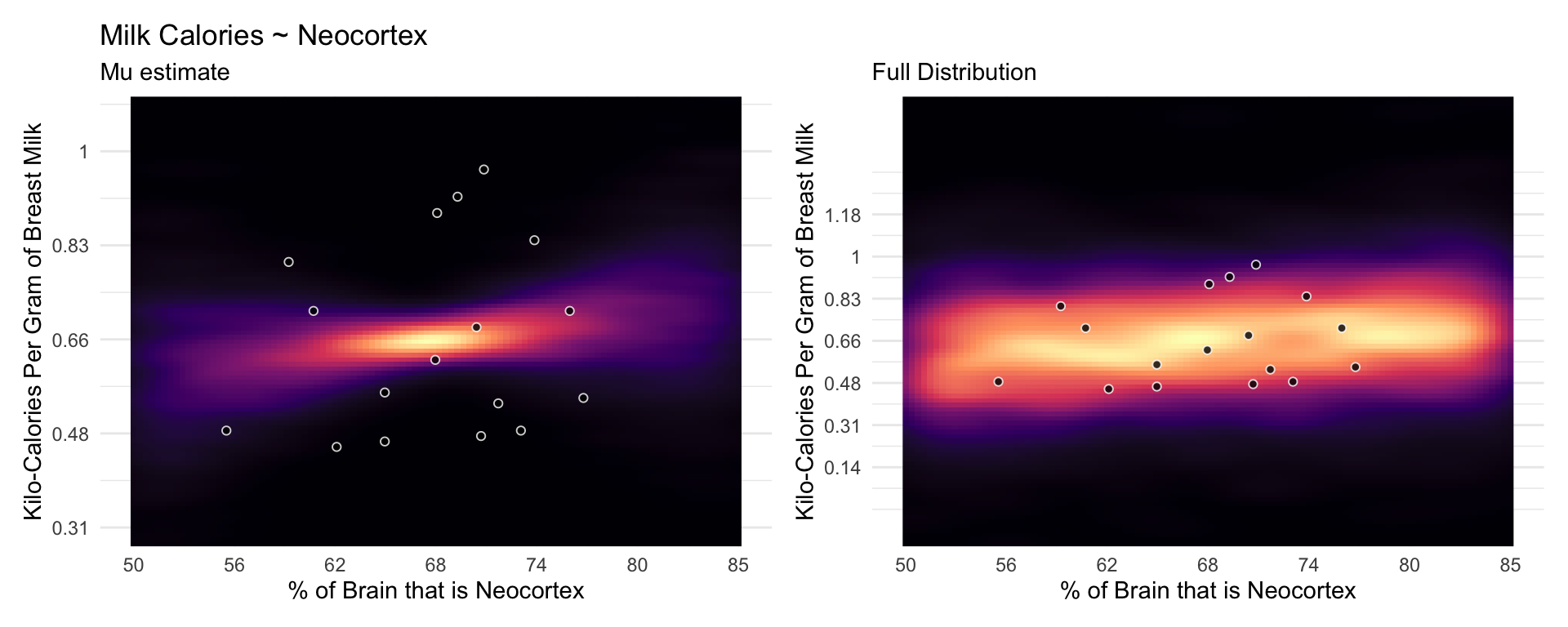
The posterior mean line is weakly positive, but it is highly imprecise. A lot of mildly positive and negative slopes are plausible, given this model and these data.
milk.01 <-
brm(data = milk2,
family = gaussian,
kcal.per.g_s ~ 1 + neocortex.perc_s,
prior = c(prior(normal(0, .2), class = Intercept),
prior(normal(0, .5), class = b),
prior(exponential(1), class = sigma)),
iter = 2000, warmup = 500, chains = 4, cores = 4,
seed = 5, backend = "cmdstanr", silent = 2,
file = "fits/milk.01.6")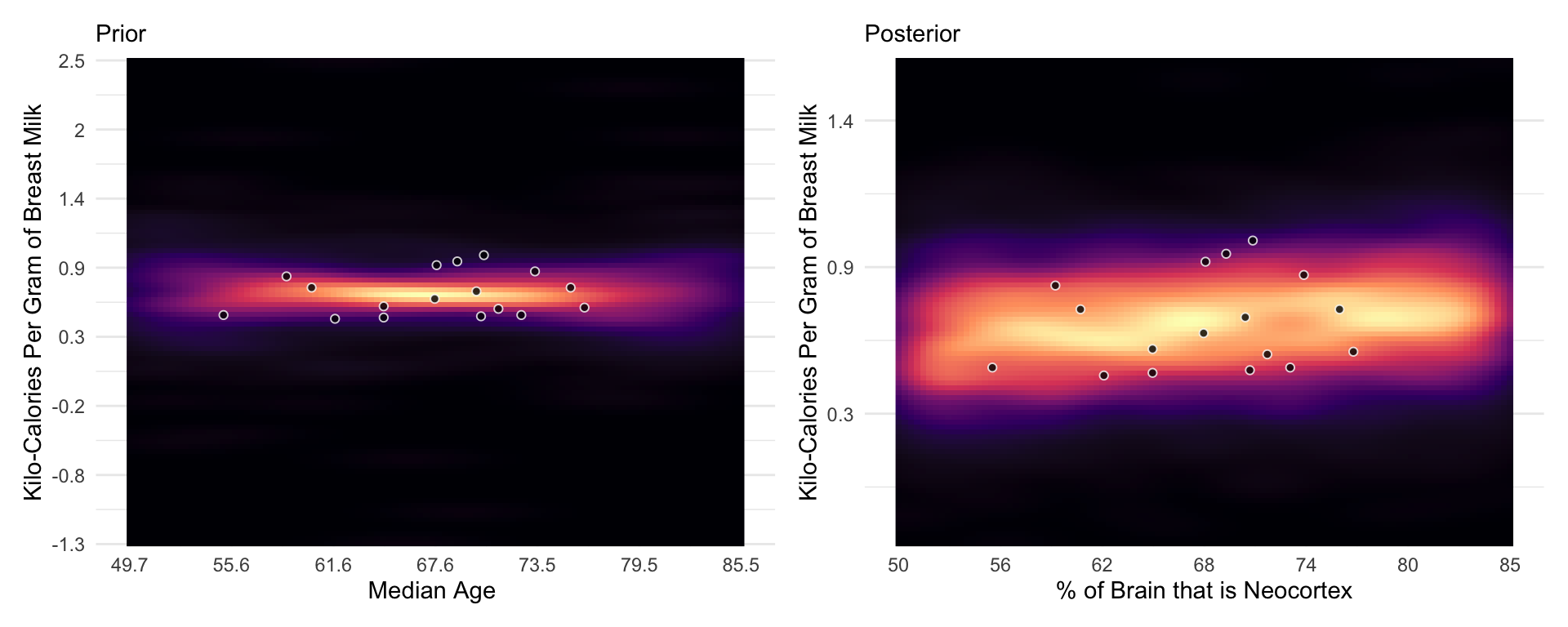
Mass Effect on Milk Calories
Now consider another predictor variable, adult female body mass, mass in the data frame. Let’s use the logarithm of mass, log(mass), as a predictor as well. Why the logarithm of mass instead of the raw mass in kilograms? It is often true that scaling measurements like body mass are related by magnitudes to other variables. Taking the log of a measure trans- lates the measure into magnitudes. So by using the logarithm of body mass here, we’re saying that we suspect that the magnitude of a mother’s body mass is related to milk energy, in a linear fashion.
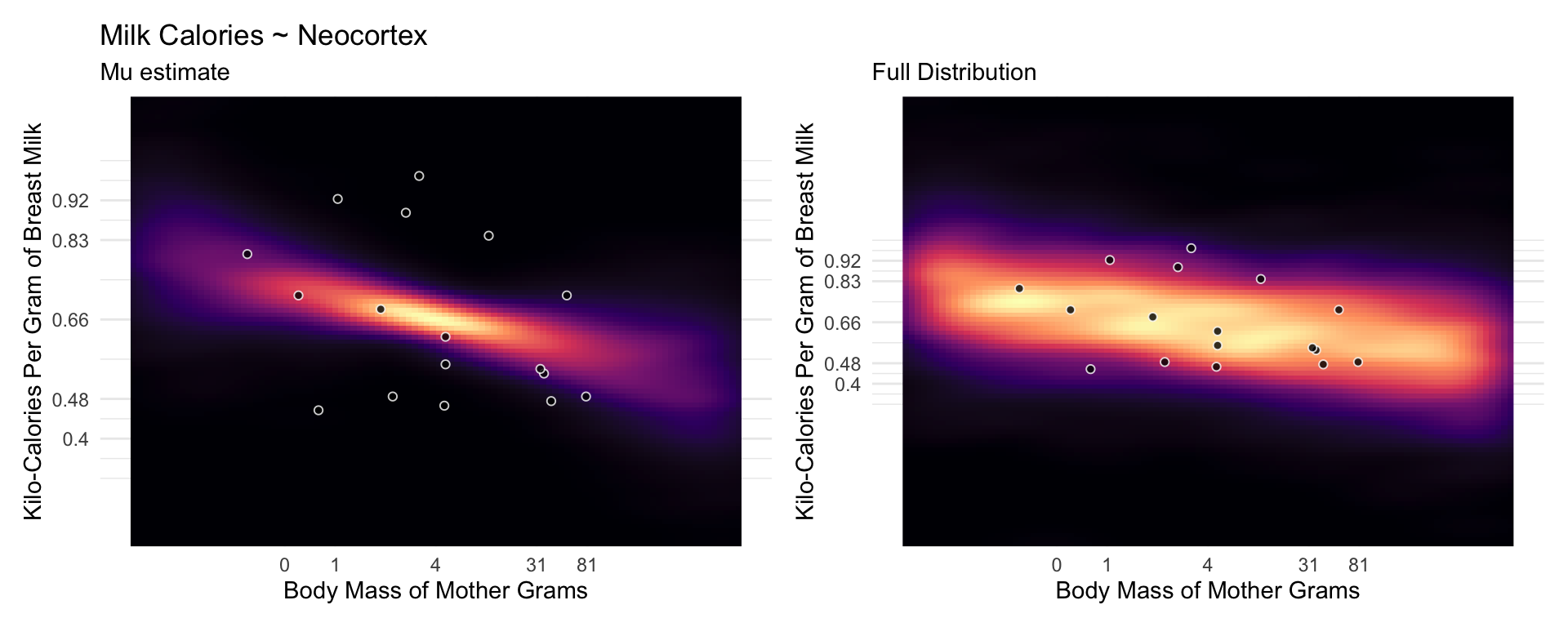
The posterior mean line is moderately negative, but it is highly imprecise.
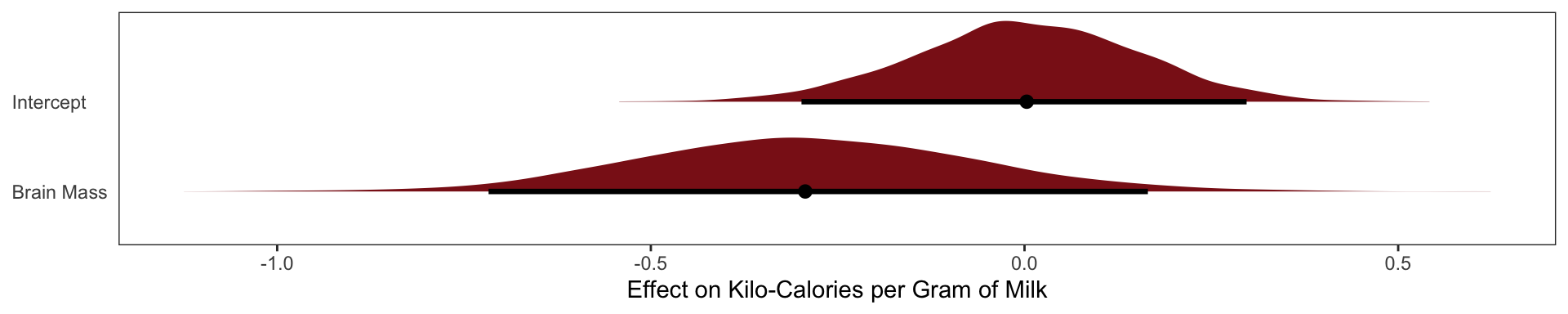
milk.02 <-
brm(data = milk2,
family = gaussian,
kcal.per.g_s ~ 1 + logMass_s,
prior = c(prior(normal(0, .2), class = Intercept),
prior(normal(0, .5), class = b),
prior(exponential(1), class = sigma)),
iter = 2000, warmup = 500, chains = 4, cores = 4,
seed = 5, backend = "cmdstanr", silent = 2,
file = "fits/milk.2.0")Multivariate Milk
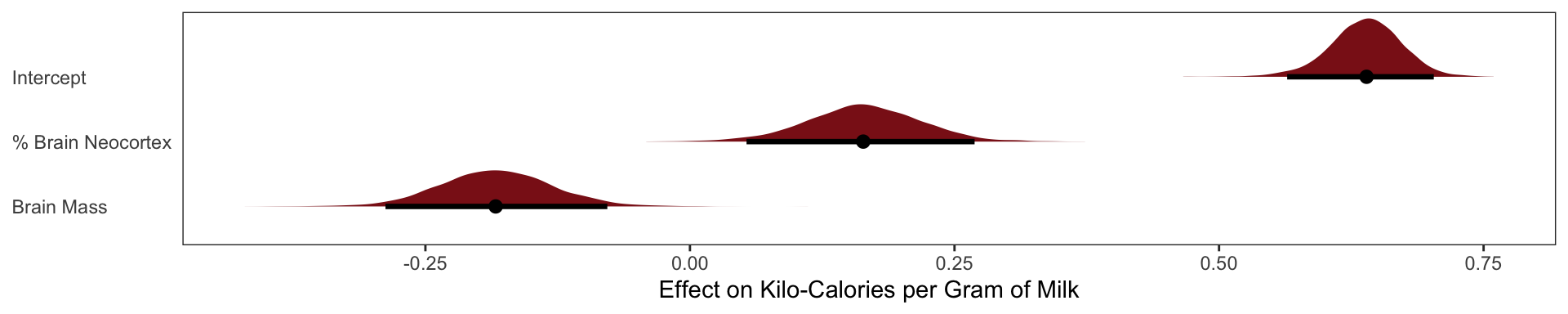
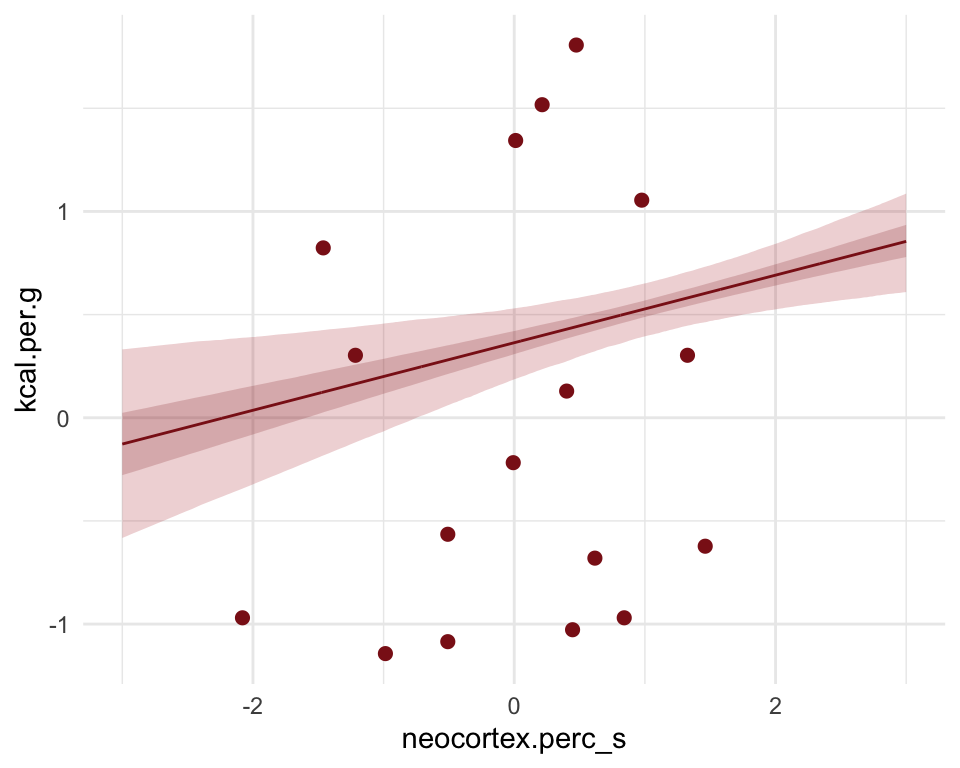
Categorical Variable
Binary Categories
Two mutually exclusive categories make the interpretation of models quite simple because it’s hard to forget that the lack of Category A implies Category B. An example, lets use male vs females as our categorical variable, with Males being represented as 1 and females as 0 in our data. The models interpretations is that the intercept is the effect of being female and the intercept + \(\beta_\text{effect of male}\) is the males effect. The same math goes into the interpretations when our categorical variables have more than 2 options, but it’s quite easy to forget that your comparing to one of the categories when you have a list of 20 categories. Always remember that you are comparing to some other category with factor effects.
Let’s go back to our Kung! height dataset we used in the last chapter. Let’s ignore the effect of weight and the other variables and focus only on sex. Our model is
\[ \text{Height}_i \sim \text{Normal(}\mu_i, \ \sigma_i\text{)}\] \[ \mu_i = \alpha + \beta_\text{male} \mathbf{I}\text{(male = 1)}\]
\[\alpha \sim \text{Normal(178, 20)}\]
\[ \beta_\text{male} \sim \text{Normal(0, 10)}\]
\[ \sigma \sim \text{Uniform(0, 50)}\]
The parameter \(\beta_\text{male}\) only influences prediction for the cases where the individual is a male. Using this approach means that \(\beta_\text{male}\) represents the expected difference between males and females in height. This makes assigning our priors a bit harder. Our approach assumes there is more uncertainty about males than females, because a male includes two parameters and therefore has two parameters.
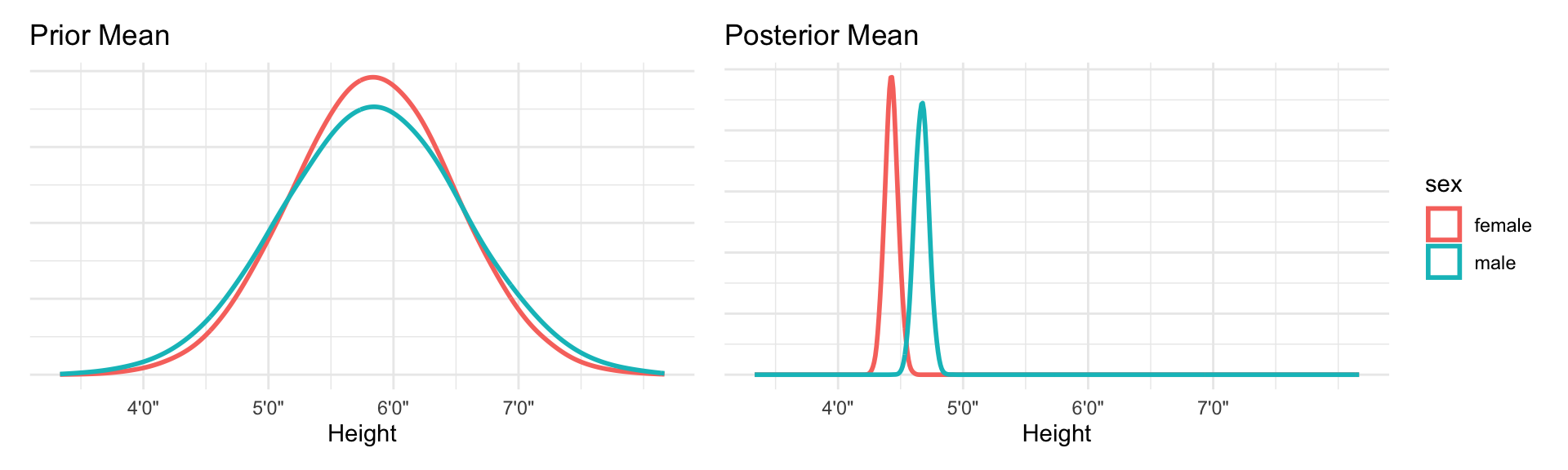
Our priors are a bit wide, and the extra variance on males doesn’t make to much sense.
A better way is to use an index variable.
\[ \text{Height}_i \sim \text{Normal(}\mu_i, \ \sigma_i\text{)}\] \[ \mu_i = \alpha_\text{Sex[i]}\]
\[\alpha_j \sim \text{Normal(178, 20), for j = 1..2}\]
\[ \sigma \sim \text{Uniform(0, 50)}\]
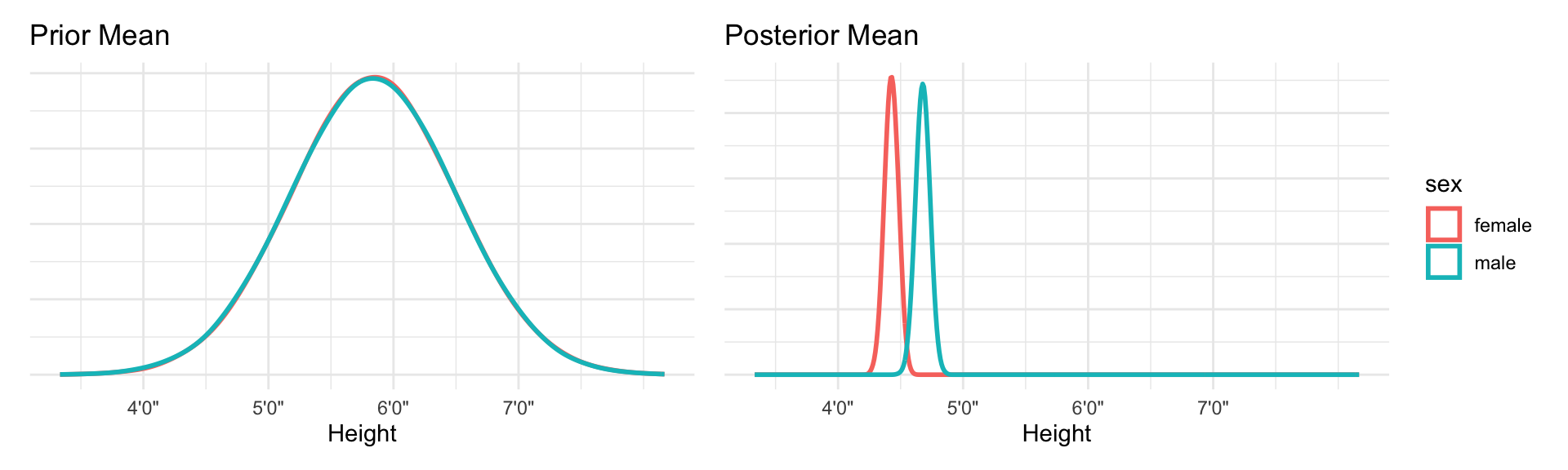
We actually care about the differences in the genders in height in this case. So for this model we simply subtract the posterior intercepts from each other to show that difference.
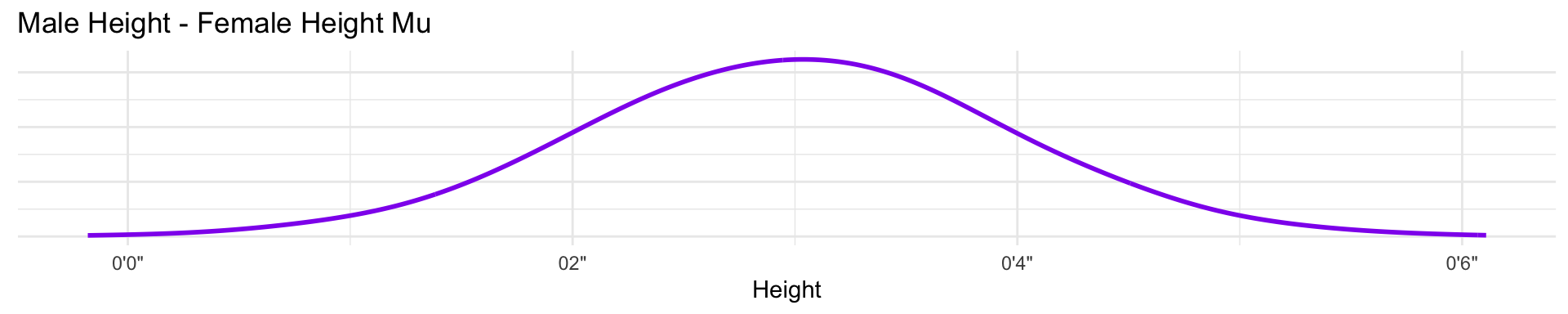
Binary categories are easy, whether you use an indicator variable or instead an index variable. But when there are more than two categories, the indicator variable approach explodes. While the index approach does not change at all when you add more categories. You do get more parameters, of course, just as many as in the indicator variable approach. But the model specification looks just like it does in the binary case. And the priors continue to be easier, unless you really do have prior information about contrasts.
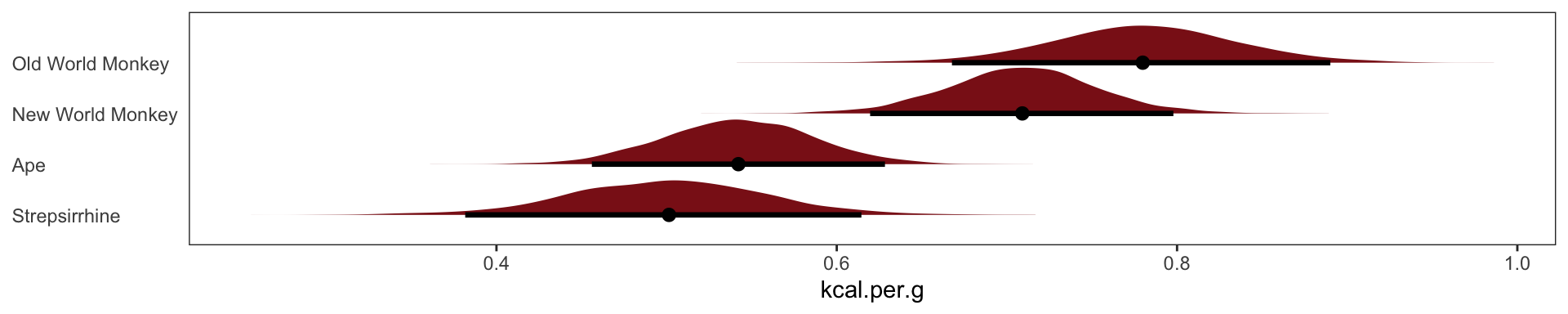
Milk example